No matter how good your docs reading and search engine querying skills are, sometimes as an R package developer you’ll need to ask questions to your peers. Where to find them? R-hub has its own feedback and discussion venues, but what about R package development in general? In this blog post, we’ll have a look at the oldest specific channel for R package development help, the R-package-devel mailing list. We’ll also mention other, younger, fora for such questions.
Brief presentation of R-package-devel
R-package-devel is one of the official mailing lists of the R project. In the words of its creators, “This list is to get help about package development in R. The goal of the list is to provide a forum for learning about the package development process. We hope to build a community of R package developers who can help each other solve problems, and reduce some of the burden on the CRAN maintainers. If you are having problems developing a package or passing R CMD check, this is the place to ask!”. It was born on May 22d, 2015 which is fairly recent; before then, R package development questions were asked on R-devel, which is now “intended for questions and discussion about code development in R.”.
To participate, you need to subscribe, and your first post will be manually moderated. After that, you’re free to post to ask or help!
To search the mailing list, you can use The Mail Archive.
Now, this is all good, but how about getting a more data-driven overview of the mailing list by downloading its archives?
Building a data.frame of R-package-devel archives
R-package-devel archives are online, organized by thread/date/author within quarters. In order to be able to get a quick glimpse at them, we first downloaded and parsed them.
Downloading all threads
In a first step, we politely scraped the archives to extract all filenames we’d then download.
session <- polite::bow("https://stat.ethz.ch/pipermail/r-package-devel/",
user_agent = "Maëlle Salmon https://masalmon.eu/")
library("magrittr")
polite::scrape(session) %>%
rvest::xml_nodes("a") %>%
xml2::xml_attr("href") %>%
.[grepl("\\.txt\\.gz", .)] -> filenames
We then downloaded each file with a pause of 5 seconds between them, still with the goal to remain polite.
fs::dir_create("archives")
download_one <- function(filename){
message(filename)
Sys.sleep(5)
download.file(glue::glue("https://stat.ethz.ch/pipermail/r-package-devel/{filename}"),
file.path("archives", filename))
}
purrr::walk(filenames, download_one)
We did this at the beginning of April, so the last complete quarter we got was the first quarter of 2019. Below is what archives held:
fs::dir_tree("archives")
## archives
## ├── 2015q2.txt.gz
## ├── 2015q3.txt.gz
## ├── 2015q4.txt.gz
## ├── 2016q1.txt.gz
## ├── 2016q2.txt.gz
## ├── 2016q3.txt.gz
## ├── 2016q4.txt.gz
## ├── 2017q1.txt.gz
## ├── 2017q2.txt.gz
## ├── 2017q3.txt.gz
## ├── 2017q4.txt.gz
## ├── 2018q1.txt.gz
## ├── 2018q2.txt.gz
## ├── 2018q3.txt.gz
## ├── 2018q4.txt.gz
## ├── 2019q1.txt.gz
## └── 2019q2.txt.gz
Parsing the threads
To parse emails, we used the tm.plugin.mail R
package,
plus one home-baked function derived from it to remove citation lines
starting with | rather than > (see e.g. this
email).
We weren’t too sure as to how to best parse emails into data.frames
thus we asked for help on rOpenSci
forum,
thanks Scott for the good advice!
We first converted all the threads to a tm.plugin.mail format.
# archives holds all the txt.gz files
filenames <- fs::dir_ls("archives")
folders <- gsub("archives\\/", "", filenames)
purrr::map2(filenames, folders,
tm.plugin.mail::convert_mbox_eml)
We wrote our own | citation-removing function.
# adapted from tm.plugin.mail source code
removeCitation2 <-
function(x)
{
citations <- grep("^[[:blank:]]*\\|", x, useBytes = TRUE)
headers <- grep("wrote:$|writes:$", x)
## A quotation header must immediately preceed a quoted part,
## possibly with one empty line in between.
headers <- union(headers[(headers + 1L) %in% citations],
headers[(headers + 2L) %in% citations])
citations <- union(headers, citations)
if (length(citations)) x[-citations] else x
}
We then wrote functions rectangling emails (that are within threads), threads (that are within folders) and folders, and applied them to the whole archive.
rectangle_email <- function(email){
email <- tm.plugin.mail::removeCitation(email, removeQuoteHeader = TRUE)
email <- tm.plugin.mail::removeMultipart(email)
email <- tm.plugin.mail::removeSignature(email)
if(is.null(email$meta$heading)){
return(NULL)
}
email$content <- removeCitation2(email$content)
tibble::tibble(author = email$meta$author,
datetime = as.POSIXct(email$meta$datetimestamp),
subject = email$meta$heading,
content = as.character(
glue::glue_collapse(email$content,
"\n")))
}
rectangle_thread <- function(thread, ID, folder){
df <- purrr::map_df(as.list(thread), rectangle_email)
if(nrow(df) == 0){
return(NULL)
}
df$thread <- paste(folder, ID, sep = "-")
return(df)
}
rectangle_folder <- function(folder){
emails <- tm::VCorpus(tm::DirSource(folder),
readerControl = list(reader = tm.plugin.mail::readMail))
threads <- tm.plugin.mail::threads(emails)
purrr::map2_df(split(emails, threads$ThreadID),
unique(rep(threads$ThreadID)),
rectangle_thread, folder = folder)
}
emails <- purrr::map_df(folders, rectangle_folder)
readr::write_csv(emails, file.path("data", "emails.csv"))
fs::dir_delete(folders)
The emails.csv file held a gigantic data.frame with one line per
email, which was our initial goal. 🎉
emails <- readr::read_csv("data/emails.csv")
str(emails)
## Classes 'spec_tbl_df', 'tbl_df', 'tbl' and 'data.frame': 3708 obs. of 5 variables:
## $ author : chr "edd at debian.org (Dirk Eddelbuettel)" "maechler at lynne.stat.math.ethz.ch (Martin Maechler)" "Dan.Kelley at Dal.Ca (Daniel Kelley)" "maechler at lynne.stat.math.ethz.ch (Martin Maechler)" ...
## $ datetime: POSIXct, format: "2015-05-22 11:38:22" "2015-05-22 14:00:13" ...
## $ subject : chr "[R-pkg-devel] Welcome all!" "[R-pkg-devel] Welcome all!" "[R-pkg-devel] how to call PROJ.4 C code in a package?" "[R-pkg-devel] how to call PROJ.4 C code in a package?" ...
## $ content : chr "\nThanks to all (176 as of now) of you for subscribing. We hope this will turn\ninto a useful forum.\n\nI woul"| __truncated__ "\n\n\nYes, the list is subscriber-only. If you are not subscribed,\nyour post is rejected immediately.\n\nHowe"| __truncated__ "The ?oce? package (for oceanographic analysis) presently includes PROJ.4 C-language source code, as a way to wo"| __truncated__ "\n\n\n\n... Well, not quite: That's not R, that was you, when you\ninstalled the CRAN package called 'proj4'.\"| __truncated__ ...
## $ thread : chr "2015q2.txt.gz-1" "2015q2.txt.gz-1" "2015q2.txt.gz-2" "2015q2.txt.gz-2" ...
## - attr(*, "spec")=
## .. cols(
## .. author = col_character(),
## .. datetime = col_datetime(format = ""),
## .. subject = col_character(),
## .. content = col_character(),
## .. thread = col_character()
## .. )
Rough exploratory data analysis (EDA) of R-package-devel-archives
Activity of the list
In total, the archives we parsed hold 3708 emails, in 1104 threads which
we define by subject (length(unique(emails$subject))). Over time,
there is no clear trend in the activity neither upwards nor downwards.
library("ggplot2")
library("magrittr")
library("ggalt")
emails %>%
dplyr::mutate(week = lubridate::round_date(datetime, unit = "week")) %>%
ggplot() +
geom_bar(aes(week)) +
hrbrthemes::theme_ipsum(base_size = 16,
axis_title_size = 16) +
xlab("Time (weeks)") +
ylab("Number of emails")
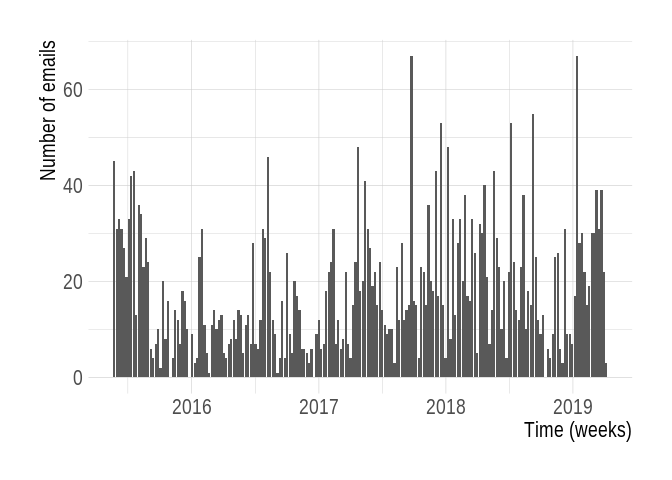
In this context of R package development help at least, email is not dead!
Who?
As mentioned earlier, the oldest email was send on 2015-05-22 10:56:21
(min(emails$datetime)). Even without cleaning email addresses too
much, it’s clear that there are some super-posters around,
dplyr::count(emails, author, sort = TRUE)
## # A tibble: 670 x 2
## author n
## <chr> <int>
## 1 edd at debian.org (Dirk Eddelbuettel) 270
## 2 murdoch.duncan at gmail.com (Duncan Murdoch) 234
## 3 ligges at statistik.tu-dortmund.de (Uwe Ligges) 185
## 4 murdoch@dunc@n @ending from gm@il@com (Duncan Murdoch) 68
## 5 h.wickham at gmail.com (Hadley Wickham) 60
## 6 ligge@ @ending from @t@ti@tik@tu-dortmund@de (Uwe Ligges) 46
## 7 edd @ending from debi@n@org (Dirk Eddelbuettel) 45
## 8 glennmschultz at me.com (Glenn Schultz) 43
## 9 csardi.gabor at gmail.com (=?UTF-8?B?R8OhYm9yIENzw6FyZGk=?=) 42
## 10 i.ucar86 at gmail.com (=?UTF-8?B?ScOxYWtpIMOaY2Fy?=) 42
## # … with 660 more rows
The above shows that there are clearly duplicates, which we won’t try to solve in this post. With this not cleaned dataset, we find 670 distinct authors. There are less than that, but still quite a lot!
What?
Of particular interest is trying to summarize the topics discussed, because they’ll reflect common hurdles that could be supported with tooling (is it difficult to reproduce issues uncovered by CRAN platforms? Yay for R-hub!) or documentation (questions about R-hub are thus gems!). Apart from reading all old threads, which is more addicting than one might think, there are some ways to extract information from the data, a few of which we’ll present here.
What are the most mentioned URL domains?
urls <- unlist(qdapRegex::rm_url(emails$content, extract = TRUE))
urls <- urls[!is.na(urls)]
urls <- urltools::url_parse(urls)
dplyr::count(urls, domain, sort = TRUE)
## # A tibble: 364 x 2
## domain n
## <chr> <int>
## 1 github.com 437
## 2 cran.r-project.org 321
## 3 stat.ethz.ch 238
## 4 win-builder.r-project.org 158
## 5 stackoverflow.com 38
## 6 www.pfeg.noaa.gov 38
## 7 dirk.eddelbuettel.com 36
## 8 www.r-project.org 36
## 9 www.keittlab.org 25
## 10 hughparsonage.github.io 22
## # … with 354 more rows
Some of these are links shared to convey information (e.g. links from GitHub or CRAN), others are actually… URLs from signatures, which we therefore haven’t been able to completely remove, too bad!
What are the subjects of emails in which R-hub ended up being mentioned?
To assess that we wrote and tested a R-hub regular expression,
"[Rr](-)?( )?[Hh]ub".
grepl("[Rr](-)?( )?[Hh]ub",
c("R hub", "Rhub", "R-hub"))
## [1] TRUE TRUE TRUE
rhub <- emails[grepl("[Rr](-)?( )?[Hh]ub", emails$content)|
grepl("[Rr](-)?( )?[Hh]ub", emails$subject),]
set.seed(42)
sample(unique(rhub$subject), 7)
## [1] "[R-pkg-devel] ORCID disappearing in auto-generated Authors: field?"
## [2] "[R-pkg-devel] Error appearing only with check_win_devel() - could be ggplot2 R version?"
## [3] "[R-pkg-devel] Build of PDF vignette fails on r-oldrel-osx-x86_64"
## [4] "[R-pkg-devel] r-hub failing?"
## [5] "[R-pkg-devel] Replicate solaris errors"
## [6] "[R-pkg-devel] registering native routines"
## [7] "[R-pkg-devel] Cannot reproduce errors for an already-accepted package"
For having read these threads, some of them contain actual promotion of R-hub services, others feature links to R-hub builder logs, which is quite cool; as well as questions about R-hub which we want to have covered in the docs.
What are the most frequent words?
stopwords <- rcorpora::corpora("words/stopwords/en")$stopWords
word_counts <- emails %>%
dplyr::select(subject) %>%
dplyr::mutate(subject = trimws(
gsub(
"\\[R\\-pkg\\-devel\\]", "", subject))) %>%
unique() %>%
tidytext::unnest_tokens(word, subject, token = "tweets") %>%
dplyr::filter(!word %in% stopwords) %>%
dplyr::count(word, sort = TRUE) %>%
dplyr::mutate(word = reorder(word, n))
ggplot(word_counts[1:15,]) +
geom_lollipop(aes(word, n),
size = 2, col = "salmon") +
hrbrthemes::theme_ipsum(base_size = 16,
axis_title_size = 16) +
coord_flip()
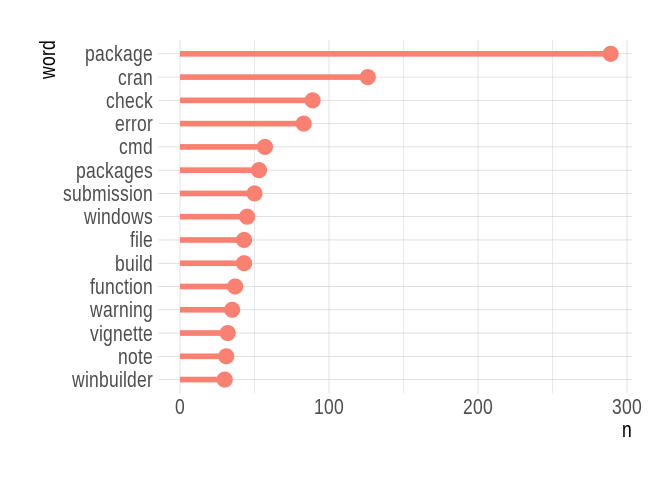
Nothing too surprising here, especially the clear dominance of “package”, followed by “cran”, “check” and “error”! Now, we could apply the same script again and again to show the most frequent bigrams (pairs of words appearing together), trigrams, etc., but we’ll take a stab at a different approach in the next section, topic modeling.
To end this EDA before attempting to model topics of the archives, here’s the longest thread of all times for you!
dplyr::count(emails, subject) %>%
dplyr::arrange(- n) %>%
dplyr::top_n(1)
## # A tibble: 1 x 2
## subject n
## <chr> <int>
## 1 [R-pkg-devel] tibbles are not data frames 50
You can read it online, it’s quite interesting! 🔥
Topic modeling of R-package-devel archives
Two blog posts of Julia Silge’s motivated us to try out topic modeling, which according to the “Tidy text mining” book by Julia Silge and David Robinson is “a method for unsupervised classification of such documents, similar to clustering on numeric data, which finds natural groups of items even when we’re not sure what we’re looking for.”. In this section, we simply adapted the code of a blog post of Julia Silge’s, “Training, evaluating, and interpreting topic models” to which you should refer for more, and very good, explanations, of the topic (hehe). A special thanks to Julia for answering our questions about the choice of the number of topics!
We first cleaned up the data a bit and re-formatted it. When tokenizing i.e. splitting by word we used the Twitter tokenizer because as explained by Julia in her blog post “it often performs the most sensibly with text from online forums”.
threads <- emails %>%
dplyr::mutate(subject = gsub("\\[R\\-pkg\\-devel\\]", "", subject),
subject = trimws(subject)) %>%
dplyr::group_by(subject) %>%
dplyr::summarise(text = glue::glue_collapse(content, sep = "\n")) %>%
dplyr::mutate(text = paste(subject, text, sep = "\n")) %>%
dplyr::mutate(text = stringr::str_replace_all(text, "'|"|/", "'"), ## weird encoding
text = stringr::str_replace_all(text, "<a(.*?)>", " "), ## links
text = stringr::str_replace_all(text, ">|<|&", " "), ## html yuck
text = stringr::str_replace_all(text, "&#[:digit:]+;", " "), ## html yuck
text = stringr::str_remove_all(text, "<[^>]*>"), ## html yuck
text = stringr::str_remove_all(text, "\\[\\[alternative HTML version deleted\\]\\]"), ## mmmmm, more html yuck
threadID = dplyr::row_number())
tidy_threads <- threads %>%
tidytext::unnest_tokens(word, text, token = "tweets") %>%
dplyr::anti_join(tidytext::get_stopwords()) %>%
dplyr::filter(!stringr::str_detect(word, "[0-9]+")) %>%
dplyr::add_count(word) %>%
dplyr::filter(n > 100) %>%
dplyr::select(-n)
threads_sparse <- tidy_threads %>%
dplyr::count(threadID, word) %>%
tidytext::cast_sparse(threadID, word, n)
We then performed topic modeling itself, with numbers of topics ranging from 5 to 50, and plotted the model diagnostics.
library("stm")
library(furrr)
plan(multiprocess)
many_models <- tibble::tibble(K = seq(5, 50, by = 1)) %>%
dplyr::mutate(topic_model = future_map(K, ~stm(threads_sparse, K = .,
verbose = FALSE)))
heldout <- make.heldout(threads_sparse)
k_result <- many_models %>%
dplyr::mutate(exclusivity = purrr::map(topic_model, exclusivity),
semantic_coherence = purrr::map(topic_model, semanticCoherence, threads_sparse),
eval_heldout = purrr::map(topic_model, eval.heldout, heldout$missing),
residual = purrr::map(topic_model, checkResiduals, threads_sparse),
bound = purrr::map_dbl(topic_model, function(x) max(x$convergence$bound)),
lfact = purrr::map_dbl(topic_model, function(x) lfactorial(x$settings$dim$K)),
lbound = bound + lfact,
iterations = purrr::map_dbl(topic_model, function(x) length(x$convergence$bound)))
library("ggplot2")
k_result %>%
dplyr::transmute(K,
`Lower bound` = lbound,
Residuals = purrr::map_dbl(residual, "dispersion"),
`Semantic coherence` = purrr::map_dbl(semantic_coherence, mean),
`Held-out likelihood` = purrr::map_dbl(eval_heldout, "expected.heldout")) %>%
tidyr::gather(Metric, Value, -K) %>%
ggplot(aes(K, Value, color = Metric)) +
geom_line(size = 1.5, alpha = 0.7, show.legend = FALSE) +
facet_wrap(~Metric, scales = "free_y") +
labs(x = "K (number of topics)",
y = NULL,
title = "Model diagnostics by number of topics",
subtitle = "We should use domain knowledge to choose a good number of topics :-)") +
hrbrthemes::theme_ipsum(base_size = 16,
axis_title_size = 16)
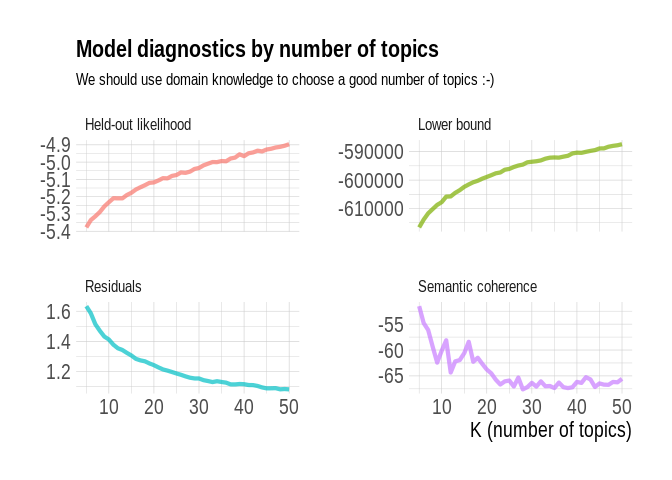
The model diagnostics plot didn’t help a ton because there was no clear best number of topics. We chose to go with 20 topics, because semantic coherence was not at its lowest yet at this number.
We then proceeded like Julia to obtain a plot summarizing the topics,
topic_model <- k_result %>%
dplyr::filter(K == 20) %>%
dplyr::pull(topic_model) %>%
.[[1]]
topic_model
## A topic model with 20 topics, 1032 documents and a 391 word dictionary.
td_beta <- tidytext::tidy(topic_model)
td_gamma <- tidytext::tidy(topic_model, matrix = "gamma",
document_names = rownames(threads_sparse))
top_terms <- td_beta %>%
dplyr::arrange(beta) %>%
dplyr::group_by(topic) %>%
dplyr::top_n(7, beta) %>%
dplyr::arrange(-beta) %>%
dplyr::select(topic, term) %>%
dplyr::summarise(terms = list(term)) %>%
dplyr::mutate(terms = purrr::map(terms, paste, collapse = ", ")) %>%
tidyr::unnest()
gamma_terms <- td_gamma %>%
dplyr::group_by(topic) %>%
dplyr::summarise(gamma = mean(gamma)) %>%
dplyr::arrange(dplyr::desc(gamma)) %>%
dplyr::left_join(top_terms, by = "topic") %>%
dplyr::mutate(topic = paste0("Topic ", topic),
topic = reorder(topic, gamma))
gamma_terms %>%
dplyr::top_n(20, gamma) %>%
ggplot(aes(topic, gamma, label = terms, fill = topic)) +
geom_col(show.legend = FALSE) +
geom_text(hjust = 0, nudge_y = 0.0005, size = 3,
family = "IBMPlexSans") +
coord_flip() +
scale_y_continuous(expand = c(0,0),
limits = c(0, 0.5),
labels = scales::percent_format()) +
hrbrthemes::theme_ipsum() +
labs(x = NULL, y = expression(gamma),
title = "20 topics by prevalence in the r-pkg-devel archives",
subtitle = "With the top words that contribute to each topic")
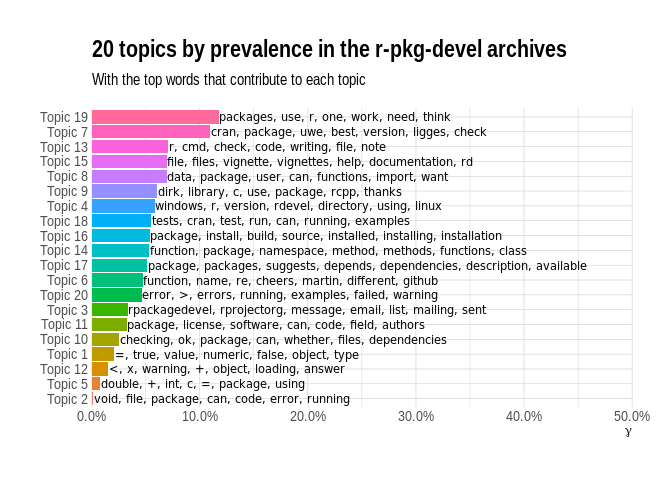
A first thing we notice about the topics is that some of them contain
the signatures of superposters: Topic 7 (“cran, package, uwe, best,
version, ligges, check”) features Uwe Ligges and CRAN; Topic 9 (“dirk,
library, c, use, package, rcpp, thanks”) puts Dirk Eddelbuettel together
with a package he maintains, Rcpp, as well as with the language C,
which makes sense (although it might be C++?). Some topics’
representative words look like fragments of code (e.g. Topic 5: “double,
+, int, c, =, package, using”), which is due to the emails containing
both text and output logs from R CMD check without special
nodes/formatting from code. Still, one could dive into Topic 15 (“file,
files, vignettes, help, documentation, rd”) to find discussions around
package documentation, and Topic 4 (“windows, r, version, rdevel,
directory, using, linux”) could refer to check results across different
R versions and OS which is a good topic for R-hub, so some of these
topics might be useful, and might help with mining the archives of, let
us remind this, 1104 threads.
Here’s how we would extract the subjects of the threads whose most probably topic is Topic 4. It is not a very good method since Topic 4 could be the most probable topic for the document without being that much more probable than other topics, but that’s a start.
td_gamma %>%
dplyr::group_by(document) %>%
dplyr::filter(gamma[topic == 4] == max(gamma)) %>%
dplyr::pull(document) %>%
unique() -> ids
set.seed(42)
unique(threads$subject[threads$threadID %in% ids]) %>%
sample(7)
## [1] "Version of make on CRAN Windows build machines"
## [2] "Windows binaries"
## [3] "Error appearing only with check_win_devel() - could be ggplot2 R version?"
## [4] "robust download function in R (similar to wget)?"
## [5] "Question about selective platform for my R package"
## [6] "object 'nativeRoutines' not found"
## [7] "R CMD check yielding different results for me than CRAN reviewer"
And here’s the same for Topic 15.
td_gamma %>%
dplyr::group_by(document) %>%
dplyr::filter(gamma[topic == 15] == max(gamma)) %>%
dplyr::pull(document) %>%
unique() -> ids
set.seed(42)
unique(threads$subject[threads$threadID %in% ids]) %>%
sample(7)
## [1] "Roxygen: function documentation to get \\item{...} in .rd file"
## [2] "separate Functions: and Datasets: indices?"
## [3] "documentation of generic '['"
## [4] "R-devel problem with temporary files or decompression?"
## [5] "No reference output from knitr vignettes"
## [6] "Indexing HTML vignette topics"
## [7] "Problem installing built vignettes"
All in all, our rough topic modelling could help us exploring the threads to identify common bottlenecks/showstoppers for R package developers.
Conclusion: R-package-devel and beyond
We’d be thrilled if you build on our rudimentary analysis here to generate a more thorough analysis of R-package-devel, please tell us if you do! As far as R mailing lists analyses are concerned, we only know of the talk “Network Text Analysis of R Mailing Lists” given at UseR! Rennes 2009 by Angela Bohn, of this search tool of R-help by Romain François and of a blog post by David Smith.
R-package-devel is definitely an active and specific venue for R package development questions, thanks a lot to its maintainers and contributors! Now, there are at least two alternatives that are actual discussion forums built on Discourse, where the threads are arguably easier to browse thanks to their being actual topics with all answers below each other, and thanks to Markdown-based formatting of code, rendering of URL’s cards in the presence of metadata, etc.:
-
RStudio community forum has a “package development” category.
-
rOpenSci community forum in particular the Questions category and the Best Practice category.
Besides, short R package development questions have most probably their place on Stack Overflow.
In all these three venues, you can’t answer by email but you can subscribe to categories/tags and have email notifications turned on so no worries if you like email a lot. 😉
Find your own favorite venue(s) for asking and answering (but beware of cross-posting!), and advertise them in your networks! In R-hub docs, a whole topic is dedicated to getting help. We hope you do find answers to all your R-hub and R package development questions!